
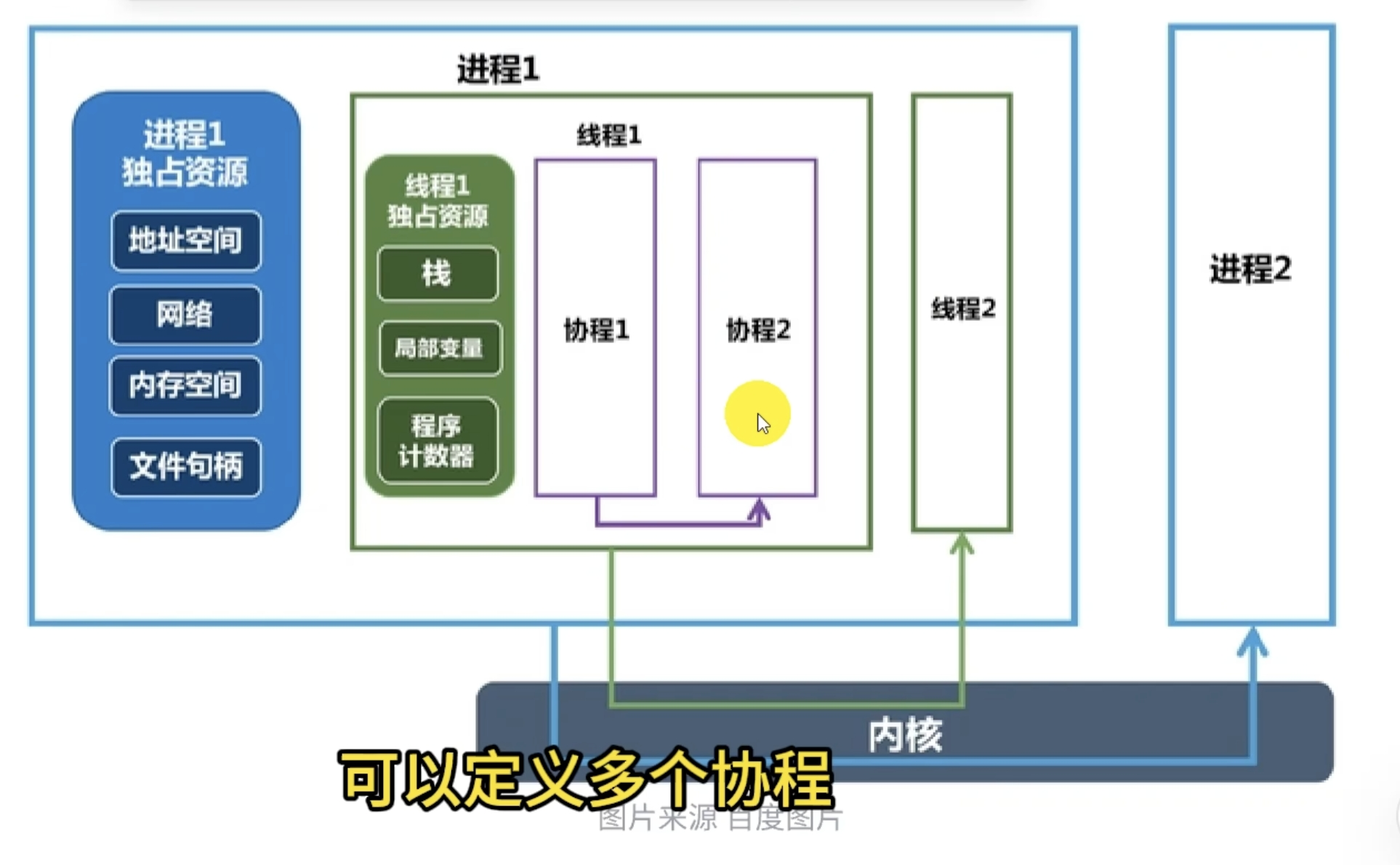
这个图里的协程应该是C++20协程。
进程和线程的区别
| 特性 | 进程 | 线程 |
|---|---|---|
| 基本单位 | 操作系统进行资源分配的基本单位 | 操作系统进行调度和执行的基本单位 |
| 资源特性 | 拥有独立的内存空间、文件句柄等系统资源 | 共享其所属进程的内存和资源(如堆、全局变量),但拥有独立的栈和寄存器 |
| 切换开销 | 高。需要切换内存地址空间、内核资源等,缓存失效风险大 | 低。主要切换寄存器、栈指针等少量状态 |
| 通信方式 | 复杂,需通过进程间通信(IPC)机制,如管道、消息队列、共享内存等 | 简单,可直接通过读写共享内存进行通信,但需注意同步问题 |
| 独立性 | 高。进程间相互隔离,一个进程崩溃通常不会影响其他进程 | 低。线程共享地址空间,一个线程崩溃可能导致整个进程及其所有线程终止 |
| 创建/销毁 | 开销大。需要分配和回收独立的内存空间等大量资源 | 开销小。因其共享进程资源,主要分配栈和寄存器等 |
| 稳定性 | 更稳定,得益于资源隔离 | 相对脆弱,因资源共享 |
线程和协程的区别
1.调度方式:内核调度 vs 用户控制
线程的调度完全由操作系统内核掌控。操作系统采用抢占式调度,即它可以在任何时候中断当前线程,转而执行另一个线程。这需要频繁地在用户态和内核态之间切换,开销较大。
协程的调度则由程序员编写的程序逻辑或语言的运行时库控制。它是一种协作式调度,协程执行到特定点(如遇到I/O操作或显式挂起)时,会主动让出控制权,从而切换到其他协程。这一切都在用户态完成,无需内核介入,开销极小。
2.资源消耗:重量级 vs 轻量级
创建一个线程需要为其分配独立的栈空间(通常默认1MB)和其他的系统资源。创建成百上千个线程会消耗大量内存,且线程间上下文切换的成本很高。
协程非常轻量,初始栈空间很小(通常仅2KB左右),且可按需动态增长。因此,单线程内可以轻松创建数万个协程而不会耗尽内存,切换开销也微乎其微。
3.执行与数据共享:并行与同步 vs 并发与协作
线程可以在多核CPU上真正并行运行,充分利用计算资源。但由于共享进程内存,访问共享数据时必须使用锁等同步机制来防止数据竞争,编程复杂且容易出错(如死锁)。
协程通常在单个线程内通过快速切换来模拟“同时”执行。因此,它们无法利用多核进行并行计算。但正因所有协程都在同一线程内顺序执行,它们共享数据时天然避免了竞争条件,大多数情况下无需复杂的锁机制,简化了编程模型。
优先选择协程的场景:
I/O密集型任务:例如处理大量网络请求、数据库操作、文件读写等。这些任务存在大量等待时间,协程可以高效地在等待时切换,极大提升吞吐量和资源利用率。
优先选择线程的场景:
CPU密集型任务:例如复杂的数学计算、图像/视频编码解码、数据分析等。这些任务需要持续占用CPU进行计算,线程可以真正在多核上并行运行,缩短总计算时间。
需要与操作系统资源(如文件描述符、硬件设备)直接紧密交互的场景。
协程比线程更轻量级(分为有栈协程和无栈协程)
协程和纤程的区别
协程是 coroutine , 是一个语言上的实现, 本质是基于线程上的上的调度, 要求协程上的代码不要做阻塞动作, 在异步操作结束后重新排队. 各个子任务之间的关系比较弱. 如果暂时都没事干, 调度者甚至会释放线程. 等到有事干的时候再开另外一个新线程. 线程并不固定.
而纤程是 fiber , 是由操作系统实现的一种轻量化线程上的一个执行结构. 通常是多个fiber共享一个固定的线程, 然后他们通过互相主动切换到其他fiber来交出线程的执行权. 各个子任务之间的关系非常强.
所以,
coroutine通常是说, 啊, 我正在等待一些事, 线程(调度者)啊你叫其他人先做吧. coroutine是排队做任务, 一张办公桌只给一个人用, 谁脑袋卡住了没事干就自觉把桌子上的东西打包走, 以后回来的话, 就跑去队列后面继续排
fiber则是, 我暂时没事干, 你(另外一个fiber)先做. fiber是主动决策哪个是接棒的fiber, 让另外一个fiber继续执行任务.
有栈和无栈的协程的区别
C++20选择了无栈协程
https://zhuanlan.zhihu.com/p/1896923067961303126
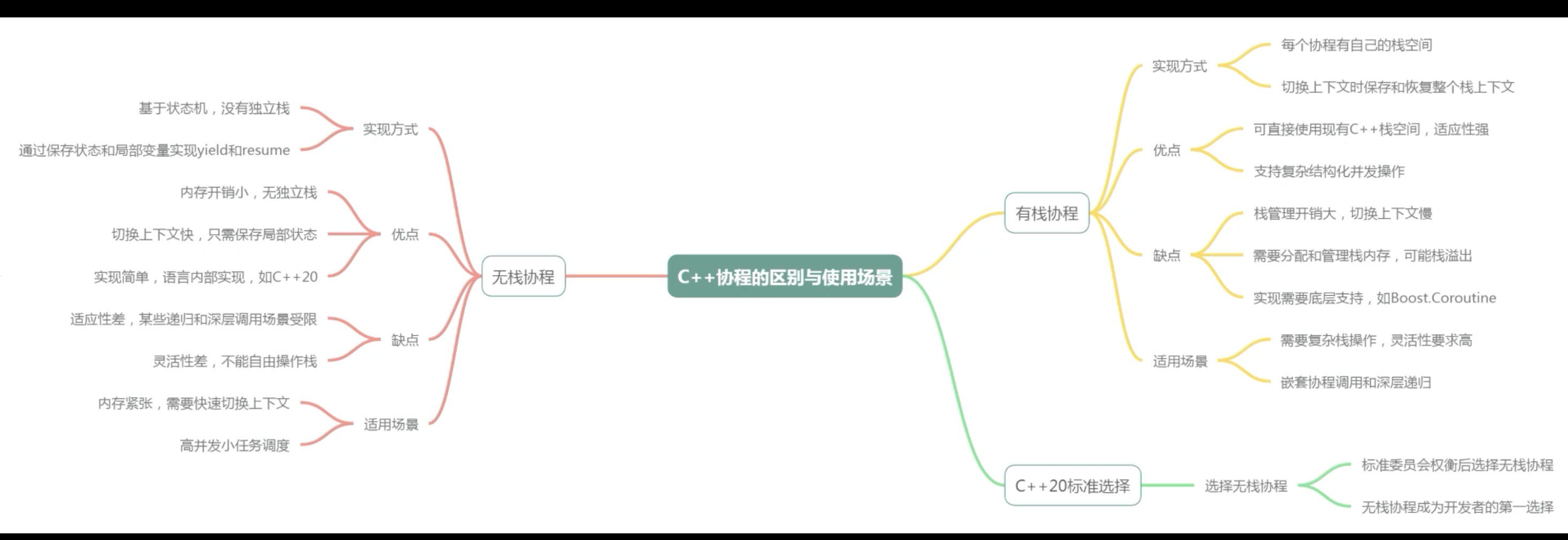
| 特性 | 有栈协程 | 无栈协程 |
|---|---|---|
| 运行状态存储 | 独立的栈空间 (通常分配于堆上,栈是模拟栈) 保存完整的上下文 | 堆上的状态对象/结构体 保存必要的局部变量和状态机信息 |
| 栈管理 | 每个协程拥有独立的调用栈,用于保存局部变量、返回地址等上下文信息 | 所有协程共享同一个栈(通常是主线程的栈)。挂起时,局部变量等状态显式保存在堆内存的状态对象中 |
| 调用能力 | ✅ 可以在任意嵌套深度、任意位置挂起和相互调用,支持对称和非对称两种调用模型 | ❌ 不能在任意嵌套函数中挂起,其"调用"本质上是状态机的组合或异步操作的链式等待 |
| 灵活性 | 高。类似于传统线程,可在函数调用链的任意一点挂起和恢复,编程模型更直观 | 低。挂起点(await点)必须在编译时确定,且通常仅限于直接包含async标记的函数顶层或特定异步操作 |
| 性能开销 | 上下文切换涉及保存和恢复整个栈及寄存器,开销相对较大 | 切换本质是状态机推进,只需处理状态对象,开销极小 |
| 内存占用 | 每个协程需预分配固定大小的栈空间,可能内存浪费或栈溢出 | 内存占用更小,状态对象通常按需分配,更节省内存 |
| 典型代表 | Golang 的 goroutine, Lua 协程 | C++20 协程, Rust 的 async/await, JavaScript 的 async/await, Python 的 Generator |
bthread和协程的区别
| 特性 | bthread | 传统协程 (如 libco) |
|---|---|---|
| 基本模型 | M:N 模型 (M个bthread映射到N个pthread) | N:1 模型 (N个协程运行于1个pthread) |
| 调度方式 | 工作窃取(Work Stealing),支持在线程间迁移 | 通常由程序自身调度,协程无法跨线程 |
| 阻塞影响 | 一个bthread阻塞不会影响其他bthread和worker线程 | 一个协程阻塞会导致其所在线程的所有协程都被阻塞 |
| 栈管理 | 有栈,采用智能栈管理机制(如栈池复用) | 多为有栈(如libco) |
| 多核利用 | 能有效利用多核(M:N模型,worker线程数与CPU核心数相关) | 难以利用多核(通常绑定单个线程,需结合多进程) |
| 设计目标 | 降低编码难度(同步编程模型)、多核扩展性、低延迟高吞吐 | 高并发I/O(配合异步I/O)、轻量级切换 |