
一、协程
优点:
- 协程消耗更少的资源:协程的创建和销毁所消耗的资源更少。
- 协程的切换更加高效:线程的切换需要进行上下文的切换,用户空间到操作系统,而协程的切换是在用户空间内完成的。
- 自主掌控协程调度:线程的调度由操作系统完成,而协程的调度可以由自己控制,更加灵活。
- 协程更易于处理复杂的异步编程:调度和切换由自己控制,更适合处理复杂的异步编程。
理解协程:
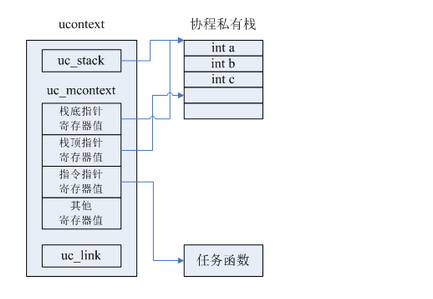
协程有三个组成要素:一个任务函数,一个存储寄存器状态的结构,一个私有栈空间(通常是malloc分配的一块内存,或者static静态区的一块内存),下面用ucontext讲述下如何实现协程的yield(挂起)和resume(开始或继续执行):
1 ucontext数据结构如下:
typedef struct ucontext
{
// 协程私有栈。
stack_t uc_stack;
// uc_mcontext结构用于缓存协程yield时,cpu各个寄存器的当前值。
mcontext_t uc_mcontext;
// uc_link指向的ucontext是后继协程的ucontext,当前协程的任务函数return后,会自动将后继协程
// 的ucontext缓存的寄存器值加载到cpu的寄存器中,cpu会去执行后继协程的任务函数(可能是从函数
// 入口点开始执行,也可能是从函数yield调用的返回点恢复执行)。
struct ucontext *uc_link;
} ucontext_t;用ucontext实现的一个协程的内存布局如下图所示:
2 ucontext的api接口:
- int getcontext(ucontext_t *ucp)
- 将cpu的各个寄存器的当前值存入当前正在被cpu执行的协程A的ucontext_t的uc_mcontext结构中。重要的寄存器有栈底指针寄存器、栈顶指针寄存器、协程A的任务函数下一条将被执行的语句的指令指针寄存器等。
- void makecontext(ucontext_t ucp, void (func)(), int argc, …)
- 指定一个协程的任务函数func以及func的argc等参数。
- int swapcontext(ucontext_t from_ucp, ucontext_t to_ucp)
- 目的是让当前协程yield,保存上下文到from_ucp,并让to_ucp对应的协程start或resume。
3 协程示例程序
下面通过一个协程示例程序,展现pthread系统线程执行多个协程切换的过程:
static ucontext_t ctx[3];
static void func_1(void) {
int a;
// 执行点2,协程1在这里yield,pthread线程恢复执行协程2的任务函数,即令协程2 resume。
swapcontext(&ctx[1], &ctx[2]);
// 执行点4,协程1从这里resume恢复执行。
// func_1 return后,由于ctx[1].uc_link = &ctx[0],将令main函数resume。
}
static void func_2(void) {
int b;
// 协程2在这里yield,pthread线程去执行协程1的任务函数func_1。
swapcontext(&ctx[2], &ctx[1]);
// 执行点3,协程2从这里resume恢复执行。
// func_2 return后,由于ctx[2].uc_link = &ctx[1],将令协程1 resume。
}
int main(int argc, char **argv) {
// 定义协程1和协程2的私有栈。
char stack_1[1024] = { 0 };
char stack_2[1024] = { 0 };
// 初始化协程1的ucontext_t结构ctx[1]。
getcontext(&ctx[1]);
// 在ctx[1]结构中指定协程1的私有栈stack_1。
ctx[1].uc_stack.ss_sp = stack_1;
ctx[1].uc_stack.ss_size = sizeof(stack_1);
// ctx[0]用于存储执行main函数所在线程的cpu的各个寄存器的值,
// 下面语句的作用是,当协程1的任务函数return后,将ctx[0]中存储的各寄存器的值加载到cpu的寄存器中,
// 也就是pthread线程从main函数之前的yield调用的返回处继续执行。
ctx[1].uc_link = &ctx[0];
// 指定协程1的任务函数为func_1。
makecontext(&ctx[1], func1, 0);
// 初始化协程2的ucontext_t结构ctx[2]。
getcontext(&ctx[2]);
// 在ctx[2]结构中指定协程2的私有栈stack_2。
ctx[2].uc_stack.ss_sp = stack_2;
ctx[2].uc_stack.ss_size = sizeof(stack_2);
// 协程2的任务函数return后,pthread线程将从协程1的yield调用的返回点处继续执行。
ctx[2].uc_link = &ctx[1];
// 指定协程2的任务函数为func_2。
makecontext(&ctx[2], func_2, 0);
// 执行点1,将cpu当前各寄存器的值存入ctx[0],将ctx[2]中存储的寄存器值加载到cpu寄存器中,
// 也就是main函数在这里yield,开始执行协程2的任务函数func_2。
swapcontext(&ctx[0], &ctx[2]);
// 执行点5,main函数从这里resume恢复执行。return 0;
}4 bthread中实现协程功能的部分
- 转到brpc中,对应ucontext的结构体为bthread_fcontext_t,结构体初始化的函数为:
bthread_fcontext_t bthread_make_fcontext(void* storage, size_t size,void (*fn)(intptr_t));- bthread中的fn为TaskGroup::task_runner()函数。
- 对应swapcontext的函数为
- intptr_t bthread_jump_fcontext(bthread_fcontext_t * from_fc, bthread_fcontext_t to_fc, intptr_t vp);
#include <bthread/context.h> // 提供 bthread_fcontext_t, bthread_make_fcontext, bthread_jump_fcontext 的定义[8,10](@ref)
#include <iostream> // 提供 std::cout, std::endl[8](@ref)
#include <utility> // 提供 std::pair, std::make_pair[8](@ref)
#include <cstdlib> // 提供 malloc 和 free 函数
bthread_fcontext_t fc_main;
bthread_fcontext_t fc;
typedef std::pair<int,int> pair_t;
static void fun_pair(intptr_t param) {
pair_t* p = (pair_t*)param;
std::cout << "point 2....." <<std::endl;
p = (pair_t*)bthread_jump_fcontext(&fc, fc_main, (intptr_t)(p->first+p->second));
std::cout << "point 4....." <<std::endl;
p = (pair_t*)bthread_jump_fcontext(&fc, fc_main, (intptr_t)(p->first+p->second));
std::cout << "point 6....." <<std::endl;
// 协程结束,跳回主上下文,传递 0 作为结束信号
bthread_jump_fcontext(&fc, fc_main, 0);
}
void test_bthread_context() {
fc_main = NULL;
std::size_t size(8192);
void* sp = malloc(size);
pair_t p(std::make_pair(2, 7));
fc = bthread_make_fcontext((char*)sp + size, size, fun_pair/*入口函数*/);
std::cout << "point 1......" <<std::endl;
// 第一次p是协程func_pair的参数
int res = (int)bthread_jump_fcontext(&fc_main, fc, (intptr_t)&p);
std::cout << "point 3......" <<p.first << " + " << p.second << " == "
<< res << std::endl;
p = std::make_pair(5, 6);
// 后面的时候,p都是作为协程func_pair内bthread_jump_fcontext的返回值
res = (int)bthread_jump_fcontext(&fc_main, fc, (intptr_t)&p);
std::cout << "point 5......." <<p.first << " + " << p.second << " == "
<< res << std::endl;
// 最后一次跳入协程,它将执行完毕并跳回
res = (int)bthread_jump_fcontext(&fc_main, fc, (intptr_t)&p);
if (res == 0) {
std::cout << "coroutine finished." << std::endl;
}
std::cout << "exit test_bthread_context......." << std::endl;
free(sp);
}
int main() {
test_bthread_context();
return 0;
}- bthread中使用函数jump_stack封装了bthread_jump_fcontext,并用类ContextualStack来管理上下文:
inline void jump_stack(ContextualStack* from, ContextualStack* to) {
bthread_jump_fcontext(&from->context, to->context, 0/*not skip remained*/);
}
struct ContextualStack {
bthread_fcontext_t context;
StackType stacktype;
StackStorage storage;
};二、bthread
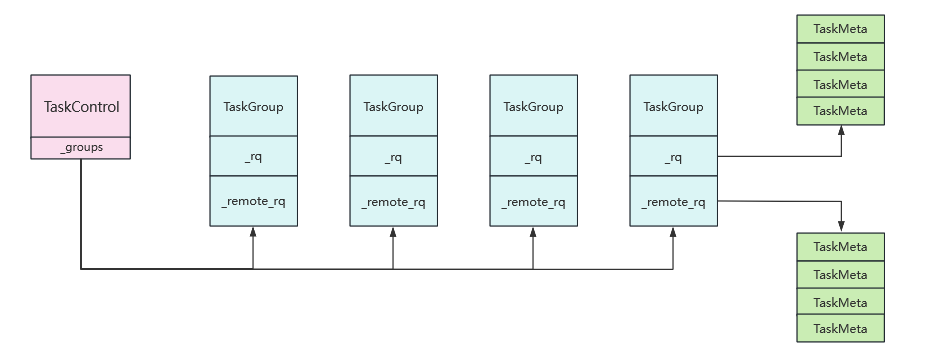
讲到bthread,首先要讲的三大件:TaskControl、TaskGroup、TaskMeta,简称TC、TG、TM。
1 TaskControl
TaskControl进程内全局唯一,看一下他的初始化函数init()。
这里的this是taskcontrol,要创建的是taskgroup
for (int i = 0; i < _concurrency; ++i) {
const int rc = pthread_create(&_workers[i], NULL, worker_thread, this);
if (rc) {
LOG(ERROR) << "Fail to create _workers[" << i << "], " << berror(rc);
return -1;}
}pthread_create的参数:
thread:指向 pthread_t类型变量的指针,用于存储新创建线程的标识符(线程ID)
attr:指向 pthread_attr_t类型线程属性对象的指针。可用于设置线程的栈大小、调度策略、分离状态等属性。若传入 NULL,则使用所有默认属性
start_routine:线程入口函数的指针。新线程创建后将从这个函数开始执行。该函数的格式必须是返回 void*且接收一个 void*类型的参数
arg:传递给线程入口函数 start_routine的参数。如果需要传递多个参数,需要将它们打包到一个结构体中,然后传递该结构体的地址
2 TaskGroup
创建的pthread内部的工作函数:
void* TaskControl::worker_thread(void* arg) {
// 1. TG创建前的处理,里面也是回调g_worker_start_fun函数来执行操作,
// 获取TC的指针
TaskControl* c = static_cast<TaskControl*>(arg);
// 2.1 创建一个TG
TaskGroup* g = c->create_group();
// 把thread local的tls_task_group 用刚才创建的TG来初始化
tls_task_group = g;
// TG运行主任务(死循环)
g->run_main_task();
}- 其中,*tls_task_group是什么概念呢?
tls_task_group是 pthread(内核线程)内部 的一个线程局部存储(Thread-Local Storage, TLS)变量,用于高效地管理和调度运行在该 pthread 上的 bthread(用户态协程)。线程局部存储(TLS)机制确保了每个 pthread 都拥有该变量的一个独立副本,且互不干扰。tls_task_group的主要作用是让每个工作线程(pthread)都能无需加锁地快速访问到自己专属的TaskGroup,从而高效地管理分配给它的 bthread 和相关队列(如本地队列_rq和远程队列_remote_rq)。这是实现高效 M:N 协程调度(如工作窃取)的基础。- 指向的对象与关系:这个指针的值在每个 bthread 的工作线程(pthread) 中,被设置为该线程所关联的
TaskGroup对象的地址。如果一个普通 pthread 的tls_task_group为NULL,则表明该线程并非 bthread 的工作线程。因此,tls_task_group是 pthread 和其专属的TaskGroup对象之间的连接桥梁。
- brpc中也将TaskGroup称之为 worker,每个线程(pthread)都有一个TaskGroup。
class TaskGroup {
ContextualStack* _main_stack;
bthread_t _main_tid;
// 无锁的本地队列
WorkStealingQueue<bthread_t> _rq;
// 有互斥锁的远端队列
RemoteTaskQueue _remote_rq;
TaskMeta* _cur_meta;
}3 TaskMeta
TaskMeta是表征bthread上下文的结构体。
struct TaskMeta {
// The identifier. It does not have to be here, however many code is
// simplified if they can get tid from TaskMeta.
bthread_t tid;
// 成员有bthread_fcontext_t和私有栈,用于实现协程切换的
ContextualStack* stack;
// User function and argument
void* (*fn)(void*);
void* arg;
}4 bthread的创建(生产者)
bthread_start_background:将新bthread放入队列后立即返回,不保证立即执行,适合非紧急任务。bthread_start_urgent:如果是在worker内调用,会让出当前worker立即执行新bthread,或将其放入队列后尽快调度,延迟更低
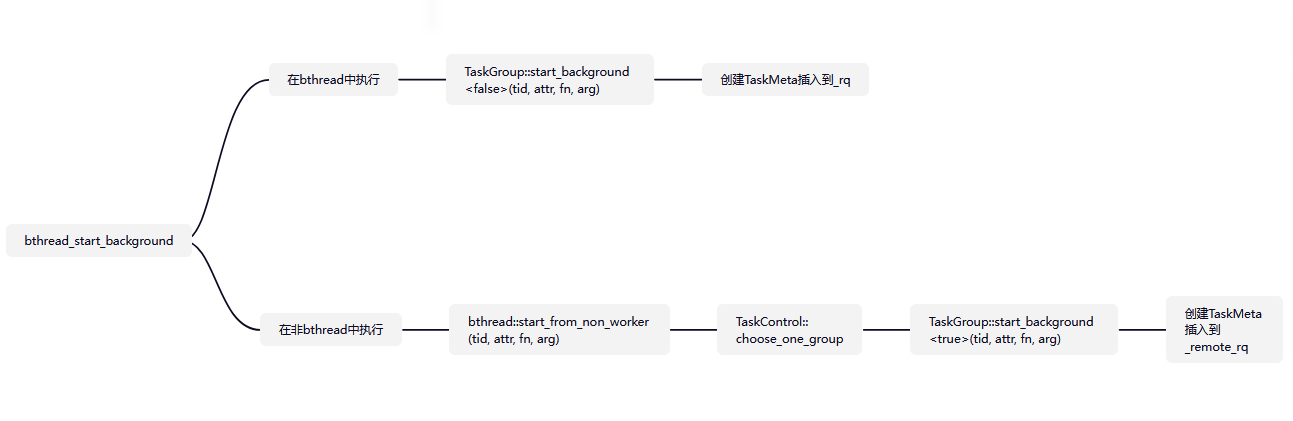
4.1 创建函数bthread_start_background
int bthread_start_background(bthread_t* __restrict tid,
const bthread_attr_t* __restrict attr,
void * (*fn)(void*),void* __restrict arg) {
bthread::TaskGroup* g = bthread::tls_task_group;
// 如果 g非空(True),说明当前正在一个bthread工作线程中执行,新创建的bthread将放入当前Worker的本地队列。
// 如果 g为空(False),说明当前在一个普通pthread中,新bthread需要放入某个Worker的远程队列
if (g) {
// start from worker
// start_background<false>的false代表是一个本地(非远程)任务提交
return g->start_background<false>(tid, attr, fn, arg);
// 这个函数会:
// (1)创建一个TaskMeta对象来保存新bthread的信息(函数 fn、参数 arg、属性 attr等)并生成唯一的 bthread_t tid
// (2)将这个新bthread放入当前 TaskGroup的本地运行队列(_rq),这是一个无锁(wait-free)队列,操作非常高效
// (3)通常不会立即唤醒其他worker线程,因为优先消耗本地队列。
}
// 只有由BRPC创建的、用于调度bthread的工作线程(worker pthread),这个指针才不为NULL。普通pthread的 tls_task_group为 NULL
return bthread::start_from_non_worker(tid, attr, fn, arg);
// 当在普通pthread中调用时,执行这个分支。
// 调用全局函数 start_from_non_worker。
// 这个函数会:
// 获取或创建全局的 TaskControl单例(管理所有工作线程和任务组)
// 随机选择一个 TaskGroup。
// 调用该 TaskGroup的 start_background<true>方法。模板参数 <true>表示这是一个远程任务提交
// 新bthread会被放入所选 TaskGroup的远程运行队列(_remote_rq),这是一个由互斥锁保护的队列
// 最后,唤醒(signal)可能处于休眠状态的worker线程来处理新任务
}创建流程:
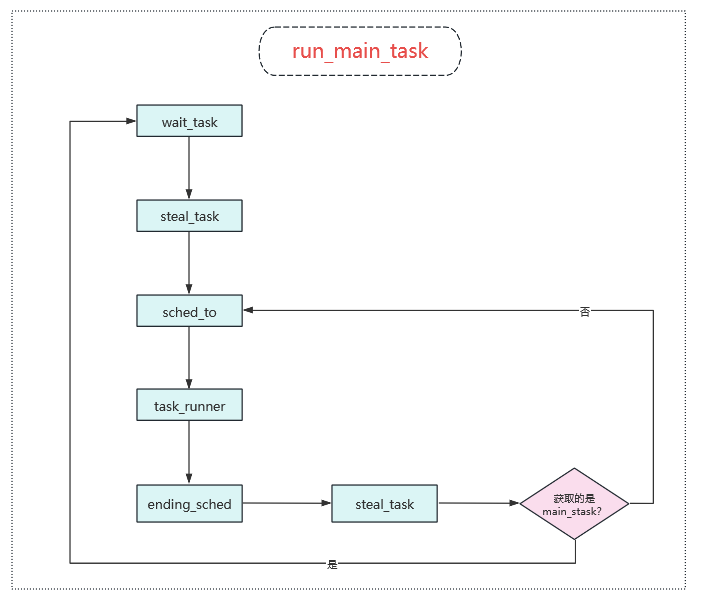
5 bthread的执行(消费者)
5.1 bthread任务执行流程图
5.2 run_main_task
void TaskGroup::run_main_task() {
TaskGroup* dummy = this;
bthread_t tid;
while (wait_task(&tid)) {
TaskGroup::sched_to(&dummy, tid);
// 当前线程的线程局部存储tls_task_group可能已经指向了被窃取任务原本所属的那个TaskGroup
DCHECK_EQ(this, dummy);
// 断言当前正在执行的任务的栈(_cur_meta->stack)就是 TaskGroup的主栈(_main_stack),即工作线程自身的内核栈。
DCHECK_EQ(_cur_meta->stack, _main_stack);
// 区分当前正在执行的任务是一个普通的 bthread 还是 TaskGroup 自身的主任务
// 自身主任务:即工作线程正处于调度循环中,没有执行用户态的 bthread)
if (_cur_meta->tid != _main_tid) {
TaskGroup::task_runner(1/*skip remained*/);
}
}
}dummy是一个指向当前工作线程的 TaskGroup的指针。其核心设计目的是为了处理工作窃取(Work Stealing) 后的上下文归属问题。在 sched_to的内部,会调用 jump_stack来进行上下文切换。如果当前工作线程通过工作窃取机制,成功从其他 TaskGroup的队列中窃取到了一个任务并执行,那么在执行完这个“窃取”来的任务后,当上下文试图切换回来时,当前线程的线程局部存储tls_task_group可能已经指向了被窃取任务原本所属的那个TaskGroup(即提供任务的那个线程组)。此时,sched_to函数会修改 *dummy(即解引用 dummy 指针),使其指向这个新的 TaskGroup地址,以反映执行环境的真实变化。
5.3 wait_task
wait_task函数获取待执行的任务,也就是bthread
bool TaskGroup::wait_task(bthread_t* tid) {
do {
// _pl是一个 ParkingLot对象,你可以将其理解为一个基于 futex 的高效等待/通知机制,类似于条件变量,但更底层、更高效
// 当调用 _pl->wait(_last_pl_state)时,当前工作线程会在此处阻塞(休眠),直到有其他线程(例如,另一个生产了任务的工作线程或主线程)向这个 ParkingLot发送通知(signal)
// 当有其他线程通过 _pl->signal()唤醒此 ParkingLot时,工作线程会从这里恢复执行。
_pl->wait(_last_pl_state);
if (steal_task(tid)) {
return true;
}
} while (true);
}5.4 steal_task
其中steal_task是bthread可以称为M:N的协程的关键
bool TaskGroup::steal_task(bthread_t* tid) {
if (_remote_rq.pop(tid)) {
return true;
}
return _control->steal_task(tid, &_steal_seed, _steal_offset);
}在当前TG的_remote_rq中拿任务,没有再去其他group中取,优先从_rq中取,再去_remote_rq中取。
任务获取通过TaskControl::steal_task来实现:
bool TaskControl::steal_task(bthread_t* tid, size_t* seed, size_t offset) {
// 1: Acquiring fence is paired with releasing fence in _add_group to
// avoid accessing uninitialized slot of _groups.
// 这行代码通过原子操作(附带获取内存屏障,memory_order_acquire)读取当前 TaskControl中管理的 TaskGroup总数 (_ngroup)。
// 内存屏障至关重要:它确保在读取 _groups数组的内容之前,一定能看到其他线程对 _ngroup和 _groups数组元素的最新修改,防止访问到未初始化的 TaskGroup槽位。注释也明确说明了这一点(避免访问未初始化的 _groups槽位)
const size_t ngroup = _ngroup.load(butil::memory_order_acquire/*1*/);
if (0 == ngroup) {
return false;
}
// NOTE: Don't return inside `for' iteration since we need to update |seed|
// stolen: 用于记录本次窃取是否成功的标志。
bool stolen = false;
// 使用随机种子是为了让不同线程或不同次窃取从不同位置开始遍历,避免多个窃取者总是竞争同一个 TaskGroup的队列,从而减少竞争。
size_t s = *seed;
// s += offset: 在每次迭代后,种子 s会增加一个 offset。offset参数通常与窃取者的标识相关,确保不同的窃取线程每次循环的步长不同,进一步分散竞争热点,避免所有窃取者步调一致。
for (size_t i = 0; i < ngroup; ++i, s += offset) {
TaskGroup* g = _groups[s % ngroup];
// g is possibly NULL because of concurrent _destroy_group
// 因为 TaskGroup可能会被并发地销毁(例如在动态调整线程池大小时),所以其指针可能为 NULL。
if (g) {
// 从其他group中取时,优先从_rq中取,再去_remote_rq中取。
if (g->_rq.steal(tid)) {
stolen = true;
break;
}
if (g->_remote_rq.pop(tid)) {
stolen = true;
break;
}
}
}
*seed = s;
return stolen;
}由此可见bthread的核心设计思想:
(1)工作窃取 (Work Stealing)
当某个工作线程自己的任务队列为空时,它不会空闲等待,而是主动从其他繁忙线程的任务队列中窃取任务来执行。这充分利用了多核资源,实现了高效的负载均衡
(2)减少竞争
- 通过随机化起点 (
seed) 和使用不同的步长 (offset),避免了所有空闲线程同时竞争同一个TaskGroup的队列,分散了压力。 - 使用无锁的
WorkStealingQueue作为主要窃取目标,其steal操作本身就是为了支持多窃取者而设计的,并发开销低
(3)双队列设计
每个 TaskGroup维护两个队列:
_rq(本地运行队列):无锁队列,存放当前 worker 自己创建的任务。窃取操作主要针对此队列。_remote_rq(远程运行队列):有锁队列,存放其他线程(普通 pthread 或其他 worker) 创建的任务。窃取时作为备用来源
PS:在if (g)之后,不会因为竞争导致g被销毁后使用吗,brpc是怎么考虑的?
如果 _destroy_group 在将 groups 数组中的指针设置为 NULL 后立即 delete g,那么这里确实会发生 use-after-free 导致的程序崩溃。
然而,bRPC 的代码能够这样写而通常不会出错,是因为它采用了一种类似于 RCU (Read-Copy-Update) 的延迟内存回收机制。这里的关键在于:将指针从 groups 数组中移除和真正释放该指针所指向的内存,这两个操作不是原子的,中间有一个重要的“宽限期”(Grace Period)。
具体来说,bRPC 的实现遵循以下逻辑:
写者(_destroy_group 线程)的操作:
- 当一个
TaskGroup需要被销毁时,写者线程会先从groups这个全局可见的数组中,将指向该TaskGroup的指针g原子地替换为NULL。 - 关键点:写者线程不会立即
delete g。相反,它会将这个指针g放入一个待回收列表中。 - 写者线程需要等待一个“宽限期”,确保系统中所有的工作线程(也就是可能正在执行
steal_task的线程)都已经经过了一个“静默状态”(Quiescent State)。静默状态意味着该线程不再持有任何可能指向旧TaskGroup的裸指针g。
读者(steal_task 线程)的操作:
- 读者线程像我们看到的代码一样,直接读取指针
g。 - 它通过
if (g)检查指针是否有效。 - 如果检查通过,它就继续使用
g。这里的隐含假设是:从我读到g到我用完g的这段极短的时间内,即使写者线程已经将它从groups数组中移除,但它所指向的内存块还不会被释放。
“宽限期”如何保证?
- 在 bRPC 的
bthread实现中,每个工作线程都会周期性地进入调度逻辑。这个调度点就可以被视为一个“静默状态”。 - 当
_destroy_group将一个TaskGroup放入待回收列表后,它会等待所有工作线程都至少完成了一次调度周期。 - 一旦所有线程都经过了这个静默状态,就意味着没有任何线程的执行栈上还保留着对那个旧
TaskGroup的裸指针引用了。这时,回收TaskGroup的内存才是安全的。
总结:
bRPC 的代码之所以看起来有风险,是因为它为了极致的性能,采用了一种无锁的、依赖于特定内存回收策略的设计。它通过将“指针置空”和“内存释放”两个操作解耦,并引入一个等待所有读者完成访问的“宽限期”,来巧妙地规避了 use-after-free 的问题。 这种设计比使用锁或 std::shared_ptr(原子引用计数)的开销要小得多,因为(steal_task)一侧几乎是零开销的,这对于一个高并发调度器至关重要。 因此,虽然代码表面上存在竞态,但整个系统的设计保证了这种竞态不会导致内存安全问题。
5.5 sched_to
获取到bthread以后,切换到对应的上下文并执行任务
inline void TaskGroup::sched_to(TaskGroup** pg, bthread_t next_tid) {
TaskMeta* next_meta = address_meta(next_tid);
// 这是一个关键的条件判断。它检查目标 bthread 的 TaskMeta中的 stack字段是否为 NULL。
// 如果为 NULL:这表明该 bthread 是首次被调度,尚未分配专用的栈空间。这时需要进入 if 语句块内为其分配栈。
// 如果不为 NULL:说明该 bthread 之前已经运行过,栈已分配,可以直接跳过分配步骤,进行后续的调度。
if (next_meta->stack == NULL) {
ContextualStack* stk = get_stack(next_meta->stack_type(), task_runner);
}
next_meta->set_stack(stk);
// Update now_ns only when wait_task did yield.
sched_to(pg, next_meta);
}这里对context了初始化,设置了入口函数为TaskGroup::task_runner
void TaskGroup::sched_to(TaskGroup** pg, TaskMeta* next_meta) {
TaskGroup* g = *pg;
TaskMeta* const cur_meta = g->_cur_meta;
// Switch to the task
// __builtin_expect是帮助分支预测的优化,告诉编译器“next_meta != cur_meta”这个条件极有可能为真
if (__builtin_expect(next_meta != cur_meta, 1)) {
// NULL是在主栈上
// 只有当前 bthread (cur_meta) 拥有自己的栈(不是运行在主栈上),并且目标 bthread (next_meta) 的栈与当前栈不同时,才会执行真正的上下文切换 jump_stack
if (cur_meta->stack != NULL) {
// 如果 next_meta->stack == cur_meta->stack,通常意味着两者共享同一个栈(例如都是主栈 _main_stack),因此无需切换
if (next_meta->stack != cur_meta->stack) {
// jump_stack封装了汇编函数bthread_jump_fcontext,操作效率极高,远超线程切换效率
jump_stack(cur_meta->stack, next_meta->stack);
// probably went to another group, need to assign g again.
// 在 jump_stack返回后,执行流可能已经发生了变化。当前工作线程可能正在为另一个TaskGroup执行任务(例如,通过工作窃取机制偷来的任务执行完毕了)。
g = tls_task_group;
}
}
}
// 当一个 bthread 主动让出 CPU 时,它需要安排一个“回调”函数,以便在将来合适的时机将自己重新加入就绪队列或其他清理工作
while (g->_last_context_remained) {
RemainedFn fn = g->_last_context_remained;
g->_last_context_remained = NULL;
// 执行回调函数 (fn) 本身可能会再次引发上下文切换(例如,回调函数会 ready 一个 bthread 并可能触发 steal),从而导致 tls_task_group改变。因此,每次循环结束后都需要重新获取 g = tls_task_group,以确保后续回调在正确的上下文中执行
// 处理剩余任务(Remained Functions):执行并清理由 yield等操作设置的延迟回调,确保 bthread 能够正确地被重新调度或进行资源清理。
fn(g->_last_context_remained_arg);
g = tls_task_group;
}
}5.6 task_runner
bthread协程的任务执行函数task_runner:
void TaskGroup::task_runner(intptr_t skip_remained) {
TaskGroup* g = tls_task_group;
// 这个条件判断是否处理上次调度留下的“剩余回调函数”。skip_remained参数为 0 时表示需要处理,非 0 则跳过。
if (!skip_remained) {
while (g->_last_context_remained) {
RemainedFn fn = g->_last_context_remained;
g->_last_context_remained = NULL;
fn(g->_last_context_remained_arg);
g = tls_task_group;
}
}
// 这个循环是 task_runner的核心,负责反复执行 bthread 任务,直到当前任务的 ID 变成 TaskGroup主任务的 ID(_main_tid),这意味着没有更多用户 bthread 需要执行,将返回调度循环
do {
// Meta and identifier of the task is persistent in this run.
TaskMeta* const m = g->_cur_meta;
void* thread_return;
try {
thread_return = m->fn(m->arg);
} catch (ExitException& e) {
thread_return = e.value();
}
// 此函数设置一个“剩余回调”,安排在当前任务执行完毕后,异步地释放任务占用的资源
g->set_remained(TaskGroup::_release_last_context, m);
ending_sched(&g);
} while (g->_cur_meta->tid != g->_main_tid);
}其中ending_sched是完成当前任务后,继续执行后续的任务。
5.7 ending_sched
结束调度与寻找新任务:ending_sched(&g);:这是一个非常重要的函数调用。它的作用是
(1)进行调度统计和记录。
(2)寻找下一个要执行的 bthread 任务。其内部会按优先级检查:
-
当前
TaskGroup的本地运行队列 (_rq)。 -
当前
TaskGroup的远程运行队列 (_remote_rq)。 -
通过工作窃取 (Work Stealing) 算法从其他
TaskGroup窃取任务。
(3)如果找到了新任务,就通过 sched_to切换到该任务的上下文并执行。
(4)如果没有找到任何任务,则会将当前任务设置为 TaskGroup的主任务 (_main_tid),这将导致 while循环条件不满足,从而退出循环。主任务代表工作线程自身的调度循环,让其进入等待或继续查找新任务的状态
void TaskGroup::ending_sched(TaskGroup** pg) {
TaskGroup* g = *pg;
bthread_t next_tid = 0;
// Find next task to run, if none, switch to idle thread of the group.
// BTHREAD_FAIR_WSQ的作用在下面
#ifndef BTHREAD_FAIR_WSQ
// 从头部取(公平)
const bool popped = g->_rq.pop(&next_tid);
#else
// 从尾部取(性能)(局部性原理)
const bool popped = g->_rq.steal(&next_tid);
#endif
if (!popped && !g->steal_task(&next_tid)) {
// Jump to main task if there's no task to run.
// 当前group的_rq没有任务,并从其他group也取不到任务时,切回到主协程。调度器会将下一个任务设置为 TaskGroup的主任务 (_main_tid)。主任务代表工作线程自身的调度循环,让其进入等待或继续查找新任务的状态
next_tid = g->_main_tid;
}
TaskMeta* const cur_meta = g->_cur_meta;
TaskMeta* next_meta = address_meta(next_tid);
// next_meta是否首次被调度
if (next_meta->stack == NULL) {
// 栈类型匹配时复用:如果目标任务 (next_meta) 与当前任务 (cur_meta) 的栈类型相同,则直接复用当前任务的栈 (cur_meta->release_stack())。这是一种优化,避免了不必要的栈分配和拷贝
if (next_meta->stack_type() == cur_meta->stack_type()) {
next_meta->set_stack(cur_meta->release_stack());
} else {
// 栈类型不匹配时新建
ContextualStack* stk = get_stack(next_meta->stack_type(), task_runner);
if (stk) {
next_meta->set_stack(stk);
} else {
// 分配失败降级:如果栈分配失败(如内存不足),则强制将任务属性降级为 BTHREAD_STACKTYPE_PTHREAD,并让其使用工作线程的主栈 (_main_stack) 运行。这意味着该 bthread 将无法被挂起和切换,像普通函数一样执行
next_meta->attr.stack_type = BTHREAD_STACKTYPE_PTHREAD;
next_meta->set_stack(g->_main_stack);
}
}
}
sched_to(pg, next_meta);
}三、其他
1 疑问
1.1 bthread是协程(coroutine)吗?
不是。我们常说的协程特指N:1线程库,即所有的协程运行于一个系统线程中,计算能力和各类eventloop库等价。由于不跨线程,协程之间的切换不需要系统调用,可以非常快(100ns-200ns),受cache一致性的影响也小。但代价是协程无法高效地利用多核,代码必须非阻塞,否则所有的协程都被卡住,对开发者要求苛刻。协程的这个特点使其适合写运行时间确定的IO服务器,典型如http server,在一些精心调试的场景中,可以达到非常高的吞吐。但百度内大部分在线服务的运行时间并不确定,且很多检索由几十人合作完成,一个缓慢的函数会卡住所有的协程。在这点上eventloop是类似的,一个回调卡住整个loop就卡住了,比如ubaserver(注意那个a,不是ubserver)是百度对异步框架的尝试,由多个并行的eventloop组成,真实表现糟糕:回调里打日志慢一些,访问redis卡顿,计算重一点,等待中的其他请求就会大量超时。所以这个框架从未流行起来。
bthread是一个M:N线程库,一个bthread被卡住不会影响其他bthread。关键技术两点:work stealing调度和butex,前者让bthread更快地被调度到更多的核心上,后者让bthread和pthread可以相互等待和唤醒。这两点协程都不需要。更多线程的知识查看这里。
1.2 在什么时候执行自身TG的_rq呢?
观察到的现象(wait_task和窃取逻辑中似乎没有直接处理本地 _rq)恰恰是 bthread 工作窃取(Work Stealing) 调度算法的一个核心设计:一个TaskGroup(Worker) 通常不会直接执行自己 _rq中的任务,而是优先让其他空闲的 TaskGroup来“窃取”执行。
这样设计的主要原因是为了减少竞争和提高缓存局部性(Cache Locality)。如果一个 Worker 同时既生产任务又消费自己生产的任务,其本地队列 _rq的竞争可能会增加。而让其他 Worker 来窃取任务,可以将工作负载更好地分散到多个 CPU 核心上。
那么,自身 _rq中的任务主要在以下时机被消费:
(1)当前任务执行完毕后的调度间隙 (ending_sched()):这是最主要的消费时机。当一个 bthread 任务(无论来自哪个队列)执行完毕(即其函数 fn(arg)返回)后,在 TaskGroup::task_runner()函数中会进行资源清理,并调用 ending_sched(&g)。在 ending_sched()函数内部,会优先从当前 TaskGroup的 _rq中获取任务。如果获取成功,就直接切换到该任务执行。如果本地 _rq为空,才会再次进入工作窃取的逻辑
(2)其他空闲 TaskGroup的工作窃取:当你看到 wait_task中的 steal_task()函数时,它的作用是一个空闲的 Worker 尝试从其他 TaskGroup窃取任务。窃取的优先级顺序是:
- 先尝试窃取其他
TaskGroup的_rq(本地运行队列)。 - 如果其他
TaskGroup的_rq也没有任务,则尝试窃取其_remote_rq(远程运行队列)
因此,自身的 _rq中的任务,很大程度上是在被其他空闲的 TaskGroup通过这种窃取机制消费掉的。
1.3 本地队列 _rq不是无锁的吗,而_remote_rq才是有锁的,为什么不直接执行_rq?
(1)_remote_rq的任务更需要”救济”:_remote_rq中的任务是由非工作线程(如普通pthread)或其他TaskGroup提交的。提交它的线程自身无法执行它,它完全依赖工作线程的调度。如果工作线程不优先处理它们,这些任务可能会长时间得不到执行,导致延迟甚至“饥饿”
(2)_rq的任务有”双重保障”:_rq中的任务是由当前Worker自己创建的。即使这个Worker暂时不执行它们,它也有很大概率在后续通过 pop操作快速消费它们。更重要的是,这些任务可以被其他空闲的Worker通过工作窃取(Work Stealing)机制偷走执行。因此,_rq中的任务有两条执行路径:本地消费和被窃取,不容易被饿死。
1.4 BTHREAD_FAIR_WSQ宏的影响
定义宏(公平模式):
- 当定义了
BTHREAD_FAIR_WSQ后,steal操作会从队列的头部取出任务。这保证了任务被窃取的顺序接近于它们被放入队列的顺序(FIFO),更公平,可以有效防止某些任务长时间得不到执行(“饥饿”现象)。
未定义宏(性能模式,默认):
-
默认情况下,
steal和pop操作都针对队列的尾部。这意味着新加入的任务和被窃取的任务都更靠近队列尾部,这种策略有利于利用CPU缓存局部性,因为最近操作的数据很可能还在缓存中,从而可以提高性能。 -
获取到bthread以后,切换到对应的上下文并执行任务
1.5 在哪些地方可能切换bthread协程
| 主动让出 | 用户代码或调度器 | bthread_jump_fcontext, jump_stack| 显式地保存当前上下文并加载新上下文。 |
| 调度器空闲 | 工作线程运行循环 | 比如TaskGroup::wait_task中调用的ParkingLot::wait()| 工作线程无任务可做时,阻塞自身等待唤醒。 |
| 同步原语 | 同步函数调用 | butex及相关锁/条件变量 | 请求的资源不可用时,bthread被挂起,切换执行其他任务。 |
| I/O操作 | 系统调用封装 | e.g.bthread_fd_*系列函数 | 执行非阻塞I/O并在未就绪时通过butex让出CPU。 |
1.6 若有大量的bthread调用了阻塞的pthread或系统函数,会影响RPC运行么?
会。比如有8个pthread worker,当有8个bthread都调用了系统usleep()后,处理网络收发的RPC代码就暂时无法运行了。只要阻塞时间不太长, 这一般没什么影响, 毕竟worker都用完了, 除了排队也没有什么好方法. 在brpc中用户可以选择调大worker数来缓解问题, 在server端可设置ServerOptions.num_threads或-bthread_concurrency, 在client端可设置-bthread_concurrency.
那有没有完全规避的方法呢?
- 一个容易想到的方法是动态增加worker数. 但实际未必如意, 当大量的worker同时被阻塞时, 它们很可能在等待同一个资源(比如同一把锁), 增加worker可能只是增加了更多的等待者.
- 那区分io线程和worker线程? io线程专门处理收发, worker线程调用用户逻辑, 即使worker线程全部阻塞也不会影响io线程. 但增加一层处理环节(io线程)并不能缓解拥塞, 如果worker线程全部卡住, 程序仍然会卡住, 只是卡的地方从socket缓冲转移到了io线程和worker线程之间的消息队列. 换句话说, 在worker卡住时, 还在运行的io线程做的可能是无用功. 事实上, 这正是上面提到的没什么影响真正的含义. 另一个问题是每个请求都要从io线程跳转至worker线程, 增加了一次上下文切换, 在机器繁忙时, 切换都有一定概率无法被及时调度, 会导致更多的延时长尾.
- 关于工作线程和IO线程的扩展:
- Brpc对不同客户端请求的读取和解析是完全并发的,用户也不用区分”IO线程“和”处理线程"。其他实现往往会区分“IO线程”和“处理线程”,并把fd(对应一个客户端)散列到IO线程中去。当一个IO线程在读取其中的fd时,同一个线程中的fd都无法得到处理。当一些解析变慢时,比如特别大的protobuf message,同一个IO线程中的其他fd都遭殃了。虽然不同IO线程间的fd是并发的,但你不太可能开太多IO线程,因为这类线程的事情很少,大部分时候都是闲着的。如果有10个IO线程,一个fd能影响到的”其他fd“仍有相当大的比例(10个即10%,而工业级在线检索要求99.99%以上的可用性)。这个问题在fd没有均匀地分布在IO线程中,或在多租户(multi-tenancy)环境中会更加恶化。在brpc中,对不同fd的读取是完全并发的,对同一个fd中不同消息的解析也是并发的。解析一个特别大的protobuf message不会影响同一个客户端的其他消息,更不用提其他客户端的消息了。
- 一个实际的解决方法是限制最大并发, 只要同时被处理的请求数低于worker数, 自然可以规避掉"所有worker被阻塞"的情况.
- 另一个解决方法当被阻塞的worker超过阈值时(比如8个中的6个), 就不在原地调用用户代码了, 而是扔到一个独立的线程池中运行. 这样即使用户代码全部阻塞, 也总能保留几个worker处理rpc的收发. 不过目前bthread模式并没有这个机制, 但类似的机制在打开pthread模式时已经被实现了. 那像上面提到的, 这个机制是不是在用户代码都阻塞时也在做"无用功"呢? 可能是的. 但这个机制更多是为了规避在一些极端情况下的死锁, 比如所有的用户代码都lock在一个pthread mutex上, 并且这个mutex需要在某个RPC回调中unlock, 如果所有的worker都被阻塞, 那么就没有线程来处理RPC回调了, 整个程序就死锁了. 虽然绝大部分的RPC实现都有这个潜在问题, 但实际出现频率似乎很低, 只要养成不在锁内做RPC的好习惯, 这是完全可以规避的.
2 Bthread的关键点
- M:N模型:bthread(M个用户态协程)由少量的pthread(N个内核线程,即worker)进行调度执行
- 双队列设计:每个
TaskGroup维护两个队列:_rq(本地运行队列):无锁队列,存放当前worker自己创建的bthread。_remote_rq(远程运行队列):有锁队列,存放其他线程(普通pthread或其他worker) 创建的bthread。- 本地队列的优先级通常高于远程队列
- 这种设计减少了竞争,提高了性能。
- 工作窃取(Work Stealing):当某个工作线程自己的任务队列为空时,它不会空闲等待,而是主动从其他繁忙线程的任务队列中窃取任务来执行。这充分利用了多核资源,实现了高效的负载均衡。
- 惰性栈分配:创建bthread时并不会立即为其分配栈空间,而是在第一次运行该bthread时才分配,这节省了内存资源
四、参考资料
bRPC的精华全在bthread上啦(一):Work Stealing以及任务的执行与切换
bRPC的精华全在bthread上啦(二):ParkingLot与Worker同步任务状态